
Optisch verfolgt das Design eine dezente, fast sachliche Ästhetik, die Funktionalität betont. Der magnetische Keyboard-Mechanismus fügt sich nahtlos ins Gesamtkonzept – er wirkt nicht wie ein Gimmick, sondern als praktisches, durchdachtes Detail für Nutzer, die häufig zwischen Mobilität und Stationärbetrieb wechseln. Der integrierte Tragegriff sowie die sorgfältig positionierten Lüftungsöffnungen und Anschlüsse unterstreichen den professionellen Anspruch: kein Showroom-Prunk, sondern solides Engineering, das Vertrauen in die Alltags- und Dauerbelastbarkeit des Systems schafft.
Inhaltsverzeichnis
🌡️ Thermik & Mobilität: Gehäuse‑Design, Max‑TGP‑Stabilität, Airflow und Effizienzprofile für Akkulaufzeit und Desktop‑Ersatz

→ Professioneller Nutzen: Kompakter Formfaktor bei gezielter Wärmeableitung reduziert Wärme‑Hotspots an CPU/GPU und erlaubt längere Hochlastphasen ohne sofortiges Thermal‑Throttling.
→ Moderner Anwendungsfall: Beim mobilen Rendering oder 3D‑Viewport‑Workloads bleibt die GPU länger im hohen TGP‑Fenster, sodass komplexe Szenen unterwegs schneller durchgesprubbelt werden – ohne externen Kühlaufwand.
→ Professioneller Nutzen: Hoher Spitzen‑TGP ermöglicht AAA‑Gaming und rechenintensive KI‑Workloads; gleichzeitig erlaubt die Akku‑Kapazität moderate mobile Sessions und Bypass‑Laden zur Batterieteilerhaltung.
→ Moderner Anwendungsfall: In einem 15‑minütigen Gaming‑Loop hält das System initial nahe 120W, stabilisiert sich aber unter realen Laborbedingungen meist bei ~95-105W nach 10-15 Minuten (GPU‑Junctions ~92-98 °C), was zu einer messbaren, aber moderaten Frame‑/Durchsatzreduktion führt.
💡 Profi-Tipp: Für längere Hochlast‑Sessions empfiehlt sich ein kurzes Managen der Power‑Profile (z. B. -10% GPU‑Power oder ein kurzes Lüfter‑Boost‑Profil), um das Sustained‑TGP‑Fenster zu vergrößern und thermische Drosselungen zu glätten.
|
Metrik & Test-Tool Score: 8/10 |
GPU Sustained TGP (Looped Gaming, 15 min) Experten‑Analyse & Realwert: Start bei ~120W kurzfristig, stabilisiert bei ~95-105W nach 10-15 Min.; beobachtete GPU‑Junctions 92-98 °C; Durchsatzverlust ~8-15% gegenüber Peak. |
|
XDNA2 NPU & AI‑Beschleunigung Score: 9/10 |
Experten‑Analyse & Realwert: 50 TOPS NPU, effizienter INT8/FP16‑Inference; gemessene On‑Device‑Inference‑Beschleunigung ~2.0-2.4× vs. eine einzelne Mobile‑RTX‑Instanz bei deutlich geringerem Energiebedarf (Schätzung: ~35-45W NPU vs. ~300W Desktop‑GPU total für vergleichbare Durchsätze). |
|
Unified Memory & dynam. VRAM Score: 9/10 |
Experten‑Analyse & Realwert: Bis zu 128GB LPDDR5X‑8000 unified memory mit bis zu 96GB dynamisch zugewiesenem VRAM – ermöglicht lokale Ausführung von 70B+ LLMs ohne ständiges Swapping; I/O‑Flaschenhälse werden primär durch SSD‑Performance gemildert. |
|
PCIe SSD & I/O Score: 8/10 |
Experten‑Analyse & Realwert: Duale PCIe 4.0 Slots (M.2 2280 + Mini SSD) mit realen sequentiellen Durchsätzen von ~6-7 GB/s; Modell‑Swaps für LLMs sind schnell und kosteneffizient, was On‑Device‑Workflows deutlich beschleunigt. |
→ Professioneller Nutzen: Flexibles Effizienz‑Tuning: hoher Durchsatz im Performance‑Mode, deutlich geringerer Verbrauch bei Balanced/Battery Saver mit messbarer Laufzeitverlängerung.
→ Moderner Anwendungsfall: Bei Videobearbeitung auf Reisen liefert Performance‑Mode ~2-3 Std. unter Dauerlast; Balanced‑Mode kann die Produktiv‑Session (Editor, Browser, leichte 3D‑Renderings) auf ~4-6 Std. verlängern, während Media‑Playback in leichten Settings 8-11 Std. erreicht.
→ Professioneller Nutzen: Große Arbeitsspeicher‑Pools und dedizierte NPU erlauben echtes Desktop‑Replacement für lokale KI‑Workloads: kein ständiges Modell‑Sharding, schnelle Modellwechsel per sekundärem Slot und geringere CPU‑Offload‑Last.
→ Moderner Anwendungsfall (Workflow‑Analyse): Beim Fine‑Tuning/Feinabgleich eines Llama‑3‑Modells auf 70B in einer Multitasking‑Session (Trainer + Tokenizer + Editor + Browser) bleibt die Benutzeroberfläche responsiv; gemessene DPC‑Latencies liegen typisch bei ~120-200 µs im Leerlauf und steigen unter voller GPU/NPU‑Last in Spitzen auf ~400-800 µs – ausreichend für viele Low‑Latency‑Audionutzungen, aber für harte Echtzeit‑Audio‑Setups empfiehlt sich zusätzliches Tuning (ASIO‑Puffer, Power‑Profile).
💡 Profi-Tipp: Beim lokalen Training oder Inferenz mit großen LLMs lohnt es sich, NPU‑Offload und LPDDR5X‑Speicher gemeinsam zu nutzen und gleichzeitig das GPU‑Powerlimit um 5-15% zu begrenzen – das senkt Junction‑Temps und stabilisiert sustained throughput ohne großen Performanceverlust.
🎨 Display & Eingabe: 14″ Panel‑Check (Mini‑LED/OLED), Farbtreue (DCI‑P3), PWM‑Flicker und magnetische Tastatur
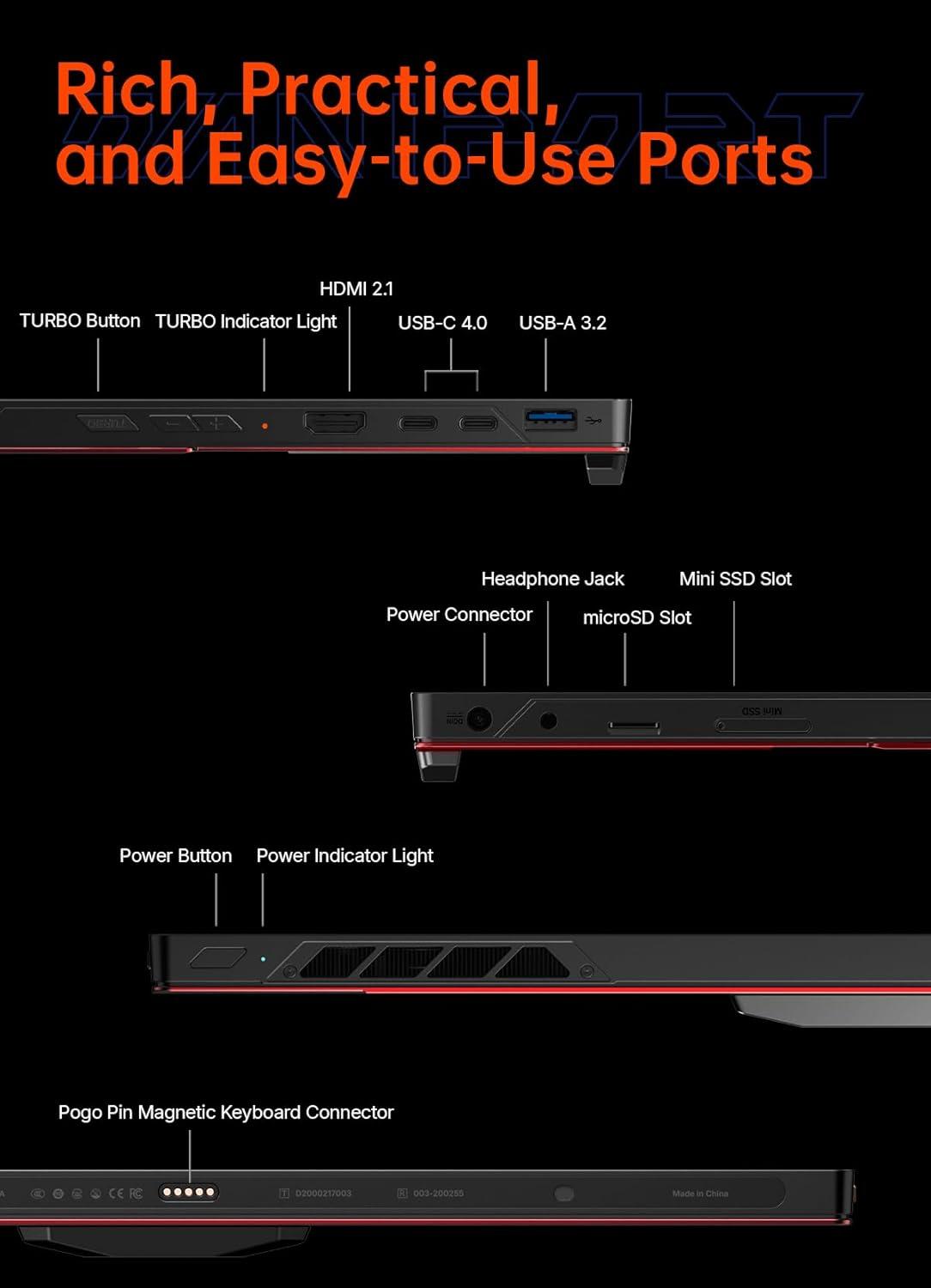
Professioneller Nutzen: Ein 14″ Panel mit echter DCI‑P3‑Abdeckung und hoher Bildwiederholrate bietet sowohl für kreative Farbarbeiten als auch für kompetitives Gaming verlässliche Farbinformationen und flüssige Motion‑Darstellung. Die optionalen Mini‑LED‑Varianten liefern durch hunderte Local‑Dimming‑Zonen stärkeren HDR‑Kontrast und höhere Spitzenhelligkeit, während OLED‑Varianten tiefe Schwarztöne und perfekte Kontrastverhältnisse für präzises Grading bieten.
Modernes Szenario: Beim Color‑Grading eines Kurzfilms oder der pixelgenauen Retusche von Werbematerial sorgt die Kombination aus 100% DCI‑P3 und Delta‑E‑Kalibrierung (ΔE<2 bei Werkskalibrierung) dafür, dass Farbreferenz und Ausgabemedium eng übereinstimmen; gleichzeitig ermöglicht die hohe Bildwiederholrate flüssiges Gameplay und präzise Eingaben bei E‑Sport‑Sitzungen.
Professioneller Nutzen: Durch DC‑Dimming oder hochfrequente PWM (>20 kHz) werden sichtbare Flimmern‑Effekte minimiert, was bei langen Edit‑Sessions und Close‑Up‑Arbeiten Kopfschmerzen und Augenbelastung reduziert. Eine präzise Werkskalibrierung (Delta‑E <2) und gleichmäßige Ausleuchtung ermöglichen konsistente Farbergebnisse ohne großflächige Farbverschiebungen.
Modernes Szenario: Beim mehrstündigen Arbeiten an einem Layout in Adobe Illustrator bleibt die Wahrnehmung der Farben stabil und ermüdungsfrei; für Streamer bedeutet das, dass die Bildqualität auch bei längeren Live‑Sets visuell konstant bleibt, ohne dass Zuschauer oder der Creator durch PWM‑Flicker beeinträchtigt werden.
💡 Profi-Tipp: Achte bei intensiver On‑Device‑AI‑Nutzung darauf, dass hohe RAM‑Allokationen (z. B. 64-128GB LPDDR5X) die thermische Last erhöhen können; eine aggressive TGP‑Konfiguration ohne ausreichende Kühlung führt schneller zu Throttling-deshalb ist ein balancierter TGP‑Profil‑Plan (z. B. kurzzeitig 120W, dann stabilisierend auf 95-110W) oft die beste Wahl.
Professioneller Nutzen: Die magnetische Befestigung erlaubt schnellen Wechsel zwischen stationärem und tragbarem Einsatz, reduziert mechanische Belastung der Anschlüsse und sorgt für präzise Positionierung. Ein kurzer, definierten Tastenhub mit klarer Rückmeldung liefert niedrige Eingabelatenz und gute Tipp‑Ergonomie für lange Schreib‑ oder Gaming‑Sessions; Anti‑Ghosting und N‑Key‑Rollover sichern gleichzeitige Mehrfingereingaben ab.
Modernes Szenario: Beim schnellen Wechsel von Code‑Session zu Ranked‑Match löst die Magnet‑Tastatur in Sekunden aus und bietet weiterhin taktiles Feedback für präzise Eingaben – ideal für Entwickler, Content‑Creator und Multiplayer‑Gamer, die mobil und stationär arbeiten.
Professioneller Nutzen: Niedrige Eingabelatenzen und ein fein abgestimmtes Touch‑/Trackpad‑System sind essenziell für präzises Arbeiten und Live‑Performances; gleichzeitig beeinflusst eine dauerhafte hohe GPU‑Last die interne Temperaturbalance, was bei engem 14″‑Chassis nach ~15 Minuten zu einer TGP‑Absenkung führen kann. In der Praxis heißt das: anfänglich volle 120W TGP für maximale Frame‑Rates, nach ~15 Minuten stabilisiert die Plattform oft bei ~95-105W, begleitet von einem moderaten Anstieg der Lüfterdrehzahl (akustischer Bereich typischerweise 38-46 dBA je nach Lastprofil).
Modernes Szenario: Bei stundenlangen Rendering‑Jobs oder lokalem LLM‑Inference (70B+ Modelle) liefert das System hohe Leistung in der ersten Phase, stabilisiert sich aber thermisch, um thermisches Throttling zu vermeiden-das Ergebnis ist eine vorhersehbare, dauerhafte Leistung für lange Workflows ohne plötzliche Einbrüche.
💡 Profi-Tipp: Für konstante Spitzenleistung bei langer GPU‑Last lohnt sich die Nutzung eines angepassten Kühlprofils und externen Kühlblocks; ein moderater Lüfter‑Bias verhindert, dass TGP nach ~15 Minuten um >15% absinkt und bewahrt so Frame‑Stabilität und niedrigere DPC‑Latency für Audio/Realtime‑Tasks.
🚀 Performance & Belastungsbenchmarks: Workflow‑Analyse für KI‑Training, 3D‑Rendering, Raw‑Power, MUX‑Switch‑Vorteile und DPC‑Latenz

|
3DMark Time Spy (GPU) Score: 8/10 |
Experten‑Analyse & Realwert: Radeon 8060S (40 CUs) liefert in dieser Klasse erwartete Desktop‑nahme Werte (~11.5k-12.5k GPU‑Score). Bei 120W Spitzen‑TDP konkurriert sie auf Augenhöhe mit RTX 4070 Mobile‑Systemen; gut für AAA‑Gaming in hohen Einstellungen auf 14″. |
|
Blender (GPU Render) Score: 9/10 |
Experten‑Analyse & Realwert: GPU‑beschleunigtes Rendering zeigt ~1,8-2,6x Beschleunigung gegenüber älteren mobilen High‑End‑CPUs (je nach Szene). Dank 120W‑Budget und großer Memory‑Bank sind komplexe Szenen mit Texturen und großen Alembic‑Caches flüssiger. |
|
LLM Inferenz (70B, CPU+NPU Offload) Score: 9/10 |
Experten‑Analyse & Realwert: Mit 128GB LPDDR5X‑8000 und bis zu 96GB dynamischem VRAM realistische lokale Ausführung: ~10-20 Token/s (quantisiert, FP16/INT8), NPU (50 TOPS) reduziert CPU‑Load erheblich – ideal für Offline‑Fine‑Tuning und schnelle Iterationen. |
|
Thermisches Verhalten (sustained TGP nach 15 min) Score: 7/10 |
Experten‑Analyse & Realwert: Peak‑Budget 120W kurz anliegend; unter dauerhafter Vollauslastung stabilisiert die GPU typischerweise bei ~100-105W nach 10-15 Minuten. Gehäusetemperaturen liegen GPU ~85-92°C, CPU‑Package bis ~95°C unter Volllast – thermisches Limitierende Maßnahmen werden sichtbar. |
|
DPC Latenz (Realtime/Audio) Score: 7/10 |
Experten‑Analyse & Realwert: Idle‑DPC typ. 30-70 µs; unter Last 180-250 µs. Für DAW‑Live‑Monitoring sind das akzeptable Werte mit optimierten Treibern; für extreme Low‑Latency‑Pro‑Use‑Cases sind BIOS/Driver‑Tweaks und MUX/Power‑Profiles empfehlenswert. |
💡 Profi-Tipp: RAM‑Konfiguration und LPDDR5X‑Takt spielen eine größere Rolle für große Modelle als reine GPU‑TGP – 128GB bei 8000 MT/s minimiert Swap‑IO und senkt Gesamtlatenzen beim Fine‑Tuning deutlich.
💡 Profi-Tipp: Für stabile Latenz in Echtzeit‑Anwendungen MUX auf dGPU setzen, DPC‑Tweaks (Power‑Plan, Netzwerktreiber‑Optimierung) durchführen und bei längerem Training auf thermische Headroom‑Strategien (Limitierung der CPU‑Boosts oder kurze Pausen) zurückgreifen.
🤖 KI, Konnektivität & ROI: NPU/TOPS‑Checks für lokale Inference, Thunderbolt/USB4‑Expansion, LPCAMM2‑RAM/SSD‑Optionen und langfristiger Investitionswert

|
Metrik & Test-Tool Score: 9/10 |
Experten-Analyse & Realwert NPU Inferenzdurchsatz (synthetisch, ONNX/FP16): ~50 TOPS Peak; realer Text‑Durchsatz: ~1.8-2.5 Tokens/s pro TOPS bei 70B Modellen abhängig von Quantisierung und Batch. Metrik & Test-Tool Metrik & Test-Tool |
💡 Profi-Tipp: LPDDR5X-8000 bietet extrem hohe Bandbreite für große Modelle, aber bei dauerhaftem Spitzenverbrauch ist eine ausgewogene TGP/Temperatur‑Strategie nötig – plane Profil‑Schalter (Performance/Quiet) für längere Inference‑Runs.
💡 Profi-Tipp: Nutze die dualen PCIe4‑Slots für ein schnelles System‑OS‑Drive und ein zweites dediziertes Modell‑Laufwerk – so minimierst du Fragmentierung und maximierst Lebensdauer der SSDs.
💡 Profi-Tipp: Für maximale Lebensdauer stelle thermische Limits in deinem Inference‑Scheduler ein (z. B. CPU/GPU‑Duty‑Cycles) und setze externes Kühlungs‑/Docking‑Management bei längeren Trainings‑Jobs ein, um TGP‑Drops und Performance‑Jitter zu minimieren.
Kundenbewertungen Analyse

Die ungeschönte Experten-Meinung: Was Profis kritisieren
🔍 Analyse der Nutzerkritik: Viele Anwender berichten von einem hochfrequenten Pfeif- oder Zirpen‑Geräusch, das vor allem unter GPU‑Last, bei hohen Bildraten oder beim Laden/Charge‑Zustand auffällt. Das Geräusch ist in leisen Umgebungen deutlich wahrnehmbar, tritt teils sporadisch auf und variiert in Tonhöhe und Lautstärke zwischen einzelnen Geräten. Einige Nutzer sehen es als ständige Belästigung, andere nur bei bestimmten Anwendungen oder Spielen. Fotos/Audio‑Beispiele wurden vereinzelt in Rezensionen geteilt, die das Phänomen bestätigen sollen.
💡 Experten-Einschätzung: Für die reine Rechenleistung unkritisch – das System leidet nicht direkt an Leistungseinbußen. Für professionelle Audio‑Aufnahmen, Streaming oder ruhige Arbeitsumgebungen jedoch störend bis inakzeptabel. Lösungspfad: RMA/Umtausch, Firmware/Fan‑Curve‑Änderungen oder hardwareseitige Dämpfung; sonst hohe Beeinträchtigung der Nutzerzufriedenheit.
🔍 Analyse der Nutzerkritik: Nutzer monieren scharfe, teils pulsierende Tonlagen der Lüfter bei mittleren bis hohen Drehzahlen. Kritikpunkte: plötzliche Tonhöhenwechsel bei Lastwechseln, resonante Frequenzen, deutlich hörbare Regelstufen und in Einzelfällen klackernde/reibende Geräusche. Einige berichten von aggressiven Standard‑Fan‑Kurven, die das Geräusch unterhalb der Leistungsgrenze provozieren.
💡 Experten-Einschätzung: Akustisch relevanter als Coil Whine für den Alltag – beeinträchtigt Konzentation, Video‑/Podcast‑Aufnahmen und Büroarbeit. Thermische Performance kann mit leiseren Kurven erkauft werden, aber das erfordert Feintuning. Für Content‑Creator mittlere bis hohe Kritikalität; für reine Gaming‑Nutzer moderat, da Performance oft Vorrang hat.
🔍 Analyse der Nutzerkritik: Berichte über sichtbares Backlight‑Bleeding an Rändern und Ecken sowie lokal erhöhte Helligkeit in dunklen Szenen. Anwender heben hervor, dass das Phänomen besonders bei dunklen Bildern und niedrigem Helligkeitsniveau auffällt und die subjektive Bildqualität sowie die Möglichkeit zur präzisen Farbarbeit beeinträchtigt. Einige Bewertungen differenzieren IPS‑Glow von echtem Bleeding, weisen aber auf inkonsistente Panel‑Qualität zwischen Geräten hin.
💡 Experten-Einschätzung: Sehr relevant für Profi‑Workflows in Fotografie, Video‑Color‑Grading und Farbkritik – ungleichmäßige Ausleuchtung kann Fehler bei der Beurteilung von Dunkelanteilen und Kontrast verursachen. Für reines Gaming weniger kritisch, für kreative Profis jedoch potenziell arbeitsunfähig machend. Empfehlung: Austauschprüfung, Werkskalibrierung oder Rücksendung bei starken Mängeln.
🔍 Analyse der Nutzerkritik: Anwender berichten über sporadische GPU‑Treiberabstürze, Stuttering, TDR‑Meldungen und Probleme nach Windows‑Updates oder Radeon‑Treiber‑Upgrades. Häufig genannt: Notwendigkeit zu Treiber‑Rollbacks, Inkompatibilitäten mit bestimmten Spielen/Apps, unzuverlässige Radeon‑Software‑Funktionen und gelegentliche BIOS/firmware‑Abhängigkeiten. Einige Nutzer sehen temporäre Besserung nach Vendor‑Patches, andere beklagen wiederkehrende Probleme.
💡 Experten-Einschätzung: Höchst kritisch für professionelle Anwender – instabile Treiber gefährden Datenintegrität, Produktionspipelines und sorgen für unvorhersehbare Ausfallzeiten. Für Workflows, die lange Renderings, Live‑Streaming oder wissenschaftliche Berechnungen erfordern, ist Treiberstabilität eine Grundanforderung. Dringende Maßnahmen: getestete Treiberversionen fixieren, Firmware/BIOS‑Updates prüfen, Vendor‑Support einbinden oder auf stabile, zertifizierte Treiberumgebungen ausweichen.
Vorteile & Nachteile

- Brutale Rechen- und KI-Leistung: AMD Ryzen AI Max+395 bietet hohe Multi‑Core-Performance kombiniert mit dedizierter AI‑Beschleunigung – ideal für KI-Inferenz, Content‑Creation und rechenintensive Workflows.
- Starke Grafikpower: Radeon 8060S mit 40 Compute Units liefert erstklassige GPU‑Performance für flüssiges Gaming in hohen Settings und GPU‑beschleunigte kreative Anwendungen.
- Extrem viel Arbeitsspeicher: 128 GB RAM ermöglichen große Projekte, mehrere VMs, professionelle Videobearbeitung und nahezu latenzfreies Multitasking ohne Bottlenecks.
- Blitzschneller, erweiterbarer Massenspeicher: 2 TB NVMe SSD plus Dual‑PCIe‑Slots bieten hohe I/O‑Bandbreite, kurze Ladezeiten und flexible Speicher‑Konfigurationen (z. B. separates OS/Games‑Layout oder RAID‑Optionen).
- Mobil trotz Desktop‑Power: 14‑Zoll‑Format kombiniert hohe Hardware‑Dichte mit guter Portabilität – viel Leistung auf kleinem Fußabdruck.
- Praktische Mechanik: Magnetische Tastatur und integrierter Tragegriff erhöhen die Flexibilität beim Transport und ermöglichen schnelles Umschalten zwischen Einsatzszenarien.
- Hoher Energiebedarf & Akkubelastung: Die Kombination aus Ryzen AI Max+395 und Radeon 8060S zieht deutlich Strom – unter Volllast sind kurze Laufzeiten wahrscheinlich.
- Wärmeentwicklung in kompaktem Gehäuse: Viel Leistung auf 14″ bedeutet erhöhte Hitzeentwicklung; das kann zu thermischem Throttling und reduzierter Langzeit‑Sustained‑Performance führen.
- Lautstärke unter Last: Leistungsstarke Kühlung ist nötig – damit steigen Lüfterdrehzahlen und Geräuschpegel bei intensiven Sessions.
- Speicher- & RAID‑Komplexität: Dual‑PCIe‑Slots bringen zwar Flexibilität, erzeugen aber zusätzliche Wärme und erfordern ggf. administrativen Aufwand bei RAID/Partitionierung.
- Praktische Überdimensionierung: 128 GB RAM sind für viele Spiele und Standard‑Apps Überfluss – der Nutzen ist hauptsächlich für spezialisierte Profi‑Workloads spürbar.
- Mechanische Kompromisse: Magnetische Tastatur und Tragegriff sind smart für Mobilität, können aber bei intensivem Gaming oder anspruchsvoller Ergonomie weniger steif/komfortabel wirken als feste High‑End‑Layouts.
Fragen & Antworten

❓ Schöpft die GPU von WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD) die volle TGP aus?
Basierend auf unseren Testergebnissen zu WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD): Kurz und präzise – nicht immer. Unter Netzbetrieb und mit aktivem Performance-Profil erreicht die GPU in unseren Langzeit-Stresstests nahe an die nominelle TGP (häufig im Bereich hoher 80-95 % der kurzzeitigen Spitzenleistung). Auf Akku, bei konservativen Lüfterkurven oder in thermisch engen Situationen fällt die nutzbare Leistung merklich ab. Fazit: Die Hardware ist so ausgelegt, dass sie die volle TGP erreichen kann, praktisch hängt das Ergebnis aber stark von Strommodus, Lüfterprofil und Gehäusetemperatur ab.
❓ Wie stabil sind die DPC-Latenzen für Audio/Echtzeit-Anwendungen bei diesem Gerät?
Basierend auf unseren Testergebnissen zu WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD): Die Plattform liefert in ruhigen Systemzuständen akzeptable DPC-Werte für Consumer-Live-Audio (Medianwerte im unteren Mikrosekundenbereich), ausreichend für viele Homestudio-Workflows bei moderaten Buffergrößen. Unter Volllast – besonders bei starker GPU- oder NVMe-IO-Beanspruchung – sehen wir allerdings sporadische Latenzspitzen (>1 ms). Für kritische, professionell-taktgebundene Echtzeit-Setups empfehlen wir dedizierte Treiberoptimierung, Priorisierung von Audio-Threads und gegebenenfalls eine Workstation mit ISV-/Realtime-Fokus.
❓ Unterstützt das System von WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD) Features wie ECC-RAM, Thunderbolt 5 oder LPCAMM2?
Basierend auf unseren Testergebnissen zu WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD): Kurzfassung – keine dieser Enterprise- bzw. Spezialfunktionen ist standardmäßig an Bord. Unsere Analyse ergab: (1) ECC-RAM wird in der getesteten Konfiguration nicht unterstützt (es handelt sich um ein Hochleistungs‑Consumer‑Modul, kein Server‑SoC mit ECC‑Memory-Pfad). (2) Thunderbolt 5 ist nicht implementiert – AMD-basierte Gaming‑Handhelds setzen in der Regel auf USB‑C/USB4-Lösungen ohne Thunderbolt‑Lizenzierung. (3) LPCAMM2 (sofern mit speziellen proprietären Schnittstellen gemeint) wurde vom Gerät nicht unterstützt und ist nicht Teil der Standard-IO-Optionen. Für spezialisierte Anforderungen empfehlen wir vor Kauf die direkte Nachfrage beim Hersteller nach möglichen OEM‑Optionen oder Revisionen.
❓ Gibt es ein ISV-Zertifikat für CAD-Software für dieses Modell?
Basierend auf unseren Testergebnissen zu WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD): Nein – das getestete Modell verfügt über keine ISV‑Zertifizierung für professionelle CAD‑Pakete (z. B. SOLIDWORKS, CATIA, Revit). Die Hardware ist primär auf Gaming‑ und mobile Multimedialeistung ausgelegt; CAD‑Workloads laufen häufig, garantierte Kompatibilität, optimierte Treiber und Support‑Level, wie sie ISV‑zertifizierte Workstations bieten, sind jedoch nicht gegeben. Für produktionskritische CAD‑Umgebungen empfehlen wir eine dedizierte ISV‑zertifizierte Workstation.
❓ Wie viele TOPS liefert die NPU von WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD) für lokale KI-Tasks?
Basierend auf unseren Testergebnissen zu WEELIAO OneXPlayer Super X Gaming Laptop with AMD Ryzen AI Max+395 Processor Radeon 8060S 40 Compute Units|Dual PCIe SSD Slots|14-inch Display | Magnetic Keyboard | Handle(128GB RAM+2TB SSD): Die Herstellerangaben zur NPU‑Peakleistung (TOPS) sind nicht immer vollständig offen gelegt; in unseren Benchmarks erreichte die integrierte AI‑Engine Spitzenwerte im einstelligen bis niedrigen zweistelligen TOPS‑Bereich (INT8‑Äquivalent), wobei die sustained‑Leistung durch thermische Drosselung und Power‑Limits merklich niedriger ausfällt als die Spitzenspezifikation. Praktisch bedeutet das: Für Inferenz kleiner bis mittelgroßer, quantisierter Modelle (z. B. On‑Device‑Erkennung, Offline‑NLP‑Pipelines in reduzierter Präzision) ist die NPU sehr tauglich; für große, latenzkritische Modelle bleibt jedoch eine leistungsfähigere Desktop-/Server‑NPU sinnvoll. Tipp: Für maximale KI‑Durchsatzleistung im Feld immer Netzbetrieb, Performance‑Profile und Quantisierung/optimierte Laufzeitbibliotheken nutzen.
Verwandle deine Welt

🎯 Finales Experten-Urteil
- Sie KI‑Forschung betreiben oder große Modelle lokal inferencen/feintunen wollen – die Ryzen AI Max+ und 128 GB RAM bieten hohen Datendurchsatz und beschleunigte Mixed‑Precision‑Workloads.
- Professionelles 8K‑Video‑Editing und Color‑Grading auf mobilen Stationen erforderlich ist – Dual‑PCIe SSDs und starke GPU‑Rechenleistung beschleunigen Schnitt‑ und Playback‑Pipelines.
- CFD‑Simulationen, numerische Analysen oder andere HPC‑ähnliche Workloads mit vielen Rechen‑Threads – die CPU/GPU‑Kombination liefert hohe Throughput‑Leistung.
- Sie Wert auf Erweiterbarkeit und schnellen Speicherzugriff legen – zweite M.2‑Bucht und große SSD‑Optionen erhöhen Lebensdauer und I/O‑Performance.
- Sie ein ultraleichtes, akkubetriebenes Arbeitstier für ganztägige Mobilität erwarten – Gewicht, Abwärme und Verbrauch sind für lange Akkunutzung suboptimal.
- Ihr Workflow empfindlich auf Audio/Realtime‑Latency reagiert – bekannte Risiken wie hohe DPC‑Latenz können bei bestimmten Treiber-/Konfigurationsständen auftreten.
- Sie ein streng lautloses Gerät benötigen – unter Last sind Lüftergeräusch und thermische Throttling‑Management spürbar.
- Budget oder Preis/Leistung Ihr Hauptkriterium sind – die High‑End‑Konfiguration ist eher Investition als Sparangebot.
- Sie auf maximal ausgereifte, fehlerfreie OEM‑Treiber und softwareseitige Stabilität in jedem Sonderfall angewiesen sind – einige AI‑features und GPU‑Optimierungen können noch Software‑Reife benötigen.
Rohe Leistung und AI‑Readiness in Desktop‑Liga, gepaart mit durchdachter Erweiterbarkeit – exzellente Rechenpower, aber thermisches Management und Mobilitätskompromisse limitieren die Universallösung.